GIAO HÀNG TOÀN QUỐC CAM KẾT BÁN ĐÚNG HÀNG CHÍNH HÃNG

Từ 8:00 - 20:00, Thứ 2 đến Chủ nhật



























Góc tư vấn
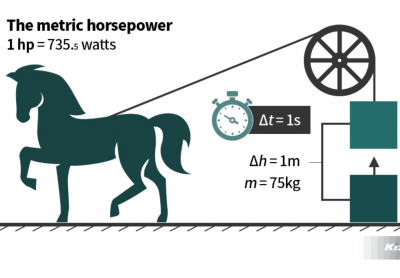
- Máy bơm 2 ngựa (Hp) bao nhiêu w | Hỏi giá máy bơm 3 ngựa bao nhiêu tiền
- Máy bơm 2 ngựa (Hp) bao nhiêu w Để trả lời được câu hỏi Máy bơm 2 ngựa (Hp) bao...

- 7 điều cần biết về bơm axit
- Bơm axit Bơm axit loãng tự mồi Thế nào là máy bơm axit? Máy bơm axit là loại máy bơm hóa chất...

- Bơm hỏa tiễn của Ý – Sản phẩm chất lượng tốt
- Bơm hỏa tiễn của Ý Trên thị trường hiện nay cung cấp rất nhiều loại máy bơm hỏa tiễn với...

- May tao oxy day ao tom Sục oxy siêu khỏe thả chìm hoặc đặt cạn
- May tao oxy day ao tom là một loại máy sục khí oxy được cải tiến có thể sục khí xuống...

- Máy bơm nước công nghiệp công suất lớn
- Máy bơm nước công nghiệp công suất lớn là gì máy bơm nước công nghiệp công suất lớn là loại...

- Tổng quan về máy bơm ly tâm – Những điều bạn chưa biết
- Bơm ly tâm có lẽ là loại máy bơm thông dụng nhất hiện nay. Với nhiều mẫu mã và chủng loại...

Khách Online
Copyright © Nhất Tâm Phát đơn vị nhập khẩu và phân phối máy bơm tại Việt Nam. All right Reserved.

